





We live in a world where all digital systems are powered by metadata. This metadata is everywhere, and sometimes in places you don’t even expect.
Metadata has been with us since the first librarian made a list of the items on a shelf of handwritten scrolls. The term "meta" comes from a Greek word that denotes "alongside, with, after, next,” and that it comes often in two forms: elements in a record alongside the item, or embedded within the item itself[The Dublin Core Metadata Initiative]
Sometimes this metadata is visible to the end user for search, but often, there’s a lot of ‘behind-the-scenes’ metadata as well; metadata that provides valuable business information about rights management, asset creation and distribution, preservation, provenance, authorship, and more




Why embedded metadata matters
Metadata is the driving force behind digital asset management, but not everyone understands how embedded metadata can be utilized to help with DAM usage. Yet there are many freely-available tools such as Phil Harvey’s EXIFTool or Python scripts to edit, apply, and manage metadata to help improve the overall DAM experience.
The embedded metadata exercises in this post can be applied to a number of different goals, so think of them as building blocks for your own embedded metadata workflows.
Example use-cases for embedded metadata
- Importing/exporting data to and from various systems
- Discovering the origin of digital asset collections for audit
- Using embedded metadata to standardize file-naming
Where does metadata live?
There are many different types of metadata, most often broken out into three main categories: descriptive metadata, structural metadata, and administrative metadata. Metadata can live within files as embedded metadata actually stored in the file itself, or it can also live outside of the file.
Sidecar metadata: A separate file that describes another file. It’s not attached or embedded in the file itself, but rather, it has a relationship to the file. Examples of sidecar metadata include .xmp files and .xml files
Platform / tool-specific metadata: Examples of platform or tool specific metadata pertains to metadata inside a particular system, for example, a DAM platform
On page markup / structured data / webpage markup / semantic web data: Structured data is essentially metadata that is used to describe elements on a webpage. Structured data extends to describe files as elements on a web page as well, and can therefore also be considered metadata that relates to digital files that are published on the web.
Embedded metadata
Embedded metadata lives inside of the resource or item that it describes. It can come in the form of a variety of different namespaces from Dublin core to custom XMP namespaces for your own company. A namespace is “a logical grouping of metadata terms. Namespaces allow unique identification of metadata terms to allow those terms to be unambiguously used across applications.” (National Archives of Australia Glossary)
This information can be applied in a variety of ways, including from within information systems you use on a daily basis to command-line interfaces to custom applications specifically designed for embedded metadata application and viewing. Note that the exercises later in this article will only focus on EXIFTool and Python, even though there are a wide variety of metadata tools available.
Some types of embedded metadata are created automatically by applications, while others, require user input. When you fill out information a “File Info” panel in an application--you are usually writing to the embedded metadata of the file itself.
Some widely used embedded metadata standards
We’re pretty wealthy when it comes to the quantity and quality of metadata standards available today. Jenn Riley’s metadata universe can give you a clear understanding of the quantity and different types of standards out there on the market today, but many are domain-specific.
Widely used standards that you’ll most commonly find while working with digital asset embedded metadata include XMP, IPTC, EXIF, and Dublin Core (Please note this is not an all-encompassing guide to metadata standards...if you need more information check out Jenn Riley’s Understanding Metadata primer from NISO.)
It’s not required to know every standard (or easily doable) In fact, in Metadata Principles and Practicalities, the authors write that application profiles allow mixing and matching schemas, because there is no one schema that perfectly meets functional requirements in all systems. You’ll find that application profiles are quite common in DAM systems.
Embedded metadata exercises
The following exercises will only focus on EXIFTool and Python, even though there are a wide variety of metadata tools available. So now that you are familiar with types of metadata and embedded metadata, the following exercises will prove useful when working with digital files, including how to:
- View and edit embedded metadata of digital files
- Rename your files using embedded metadata
- Export embedded metadata from digital files to a CSV or TXT file
- Pair two exported metadata files (CSV) on a single key using Python and use this data to enrich your assets with example product data
So to get started, you’ll need to download the following:
Just getting started with terminal or command line? Learn the Command Line at Code Academy.
Exercise 1: How can I view the embedded metadata of a digital file?
This exercise is useful for exploring what types of data are already in a file, its origin and creation, and opportunities for enrichment.
Steps to reproduce this exercise yourself:
1. Open up Terminal or a Shell window and cd to where your files are located. Example:
cd /Users/EmilyKolvitz/Desktop
2. Type the command “exiftool yourfilename.jpg or path to file, i.e.
exiftool /Users/EmilyKolvitz/Desktop/Foldername/ to scan the entire folder itself.
*hint* use -X if you want to see namespaces like this:
exiftool -X /Users/EmilyKolvitz/Desktop/Foldername
3. Take a look at the data available for the file. Example:
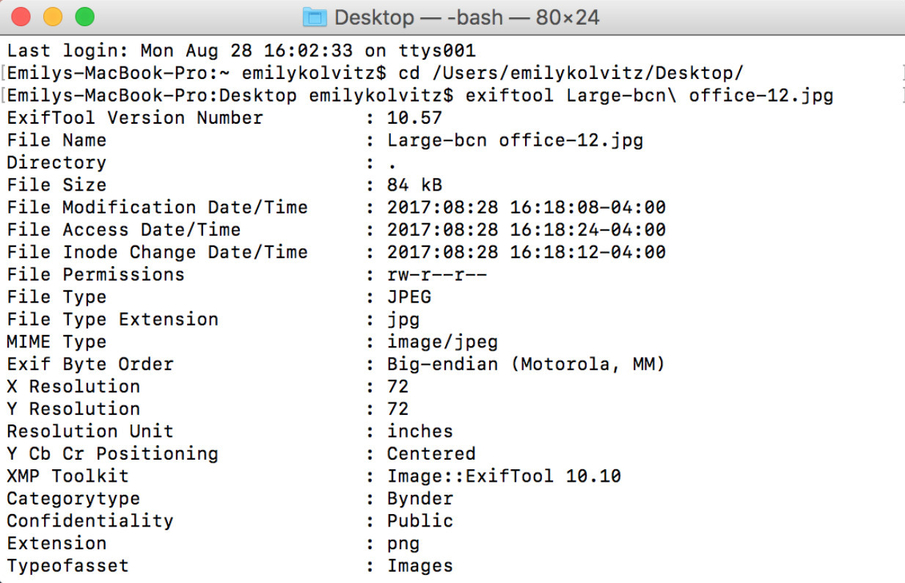
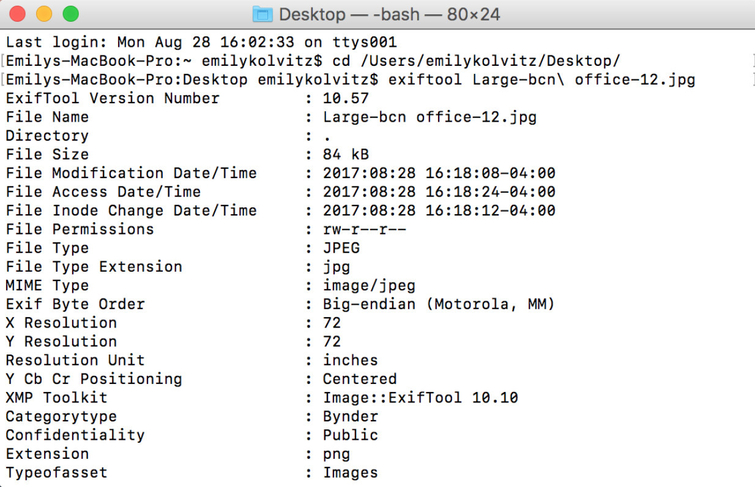
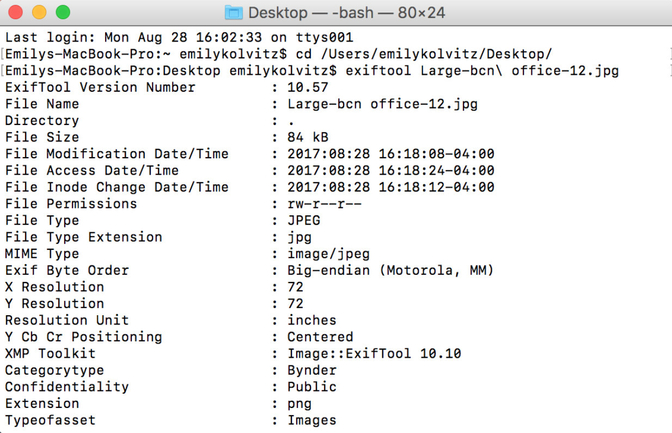
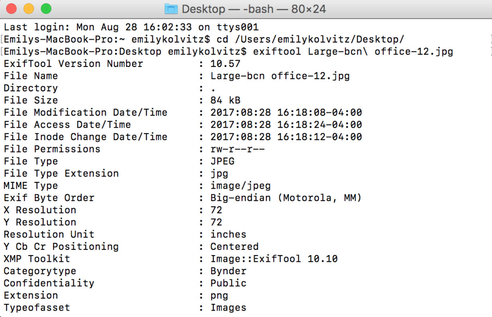
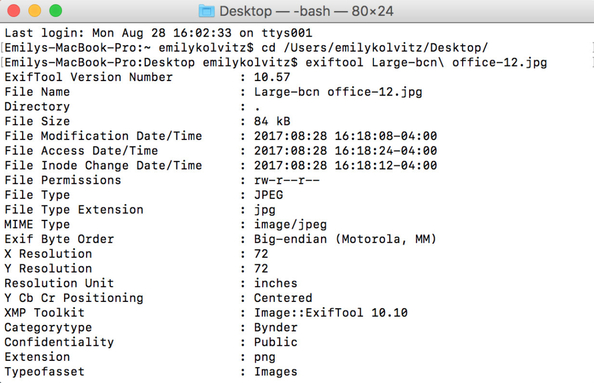
Exercise 2: How can I edit the embedded metadata of a digital file?
This exercise will help you to manipulate and enrich metadata for large sets of digital assets. It’s a batch-process for automating repetitive, time-consuming data application.
- Open terminal/shell window and cd to your location for files, just like in Exercise 1
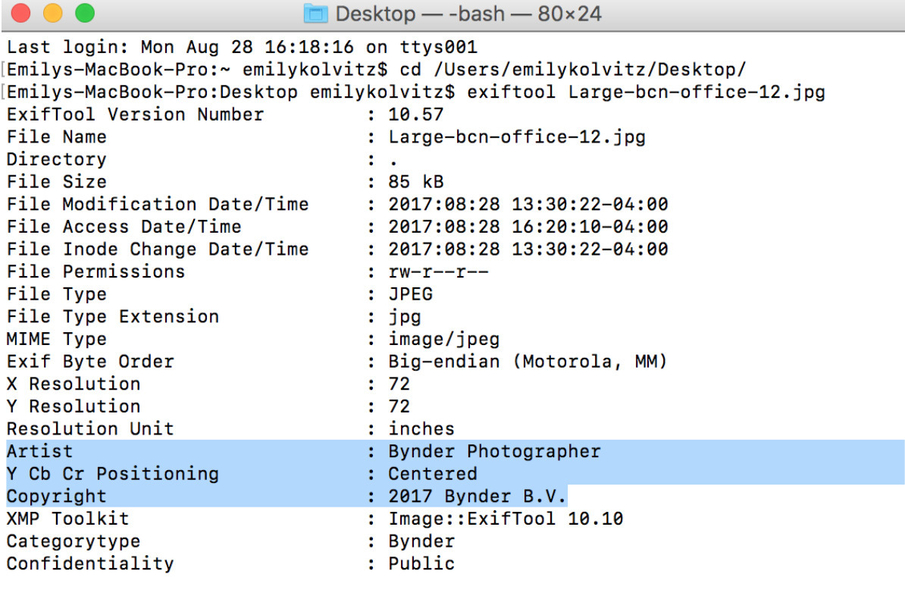
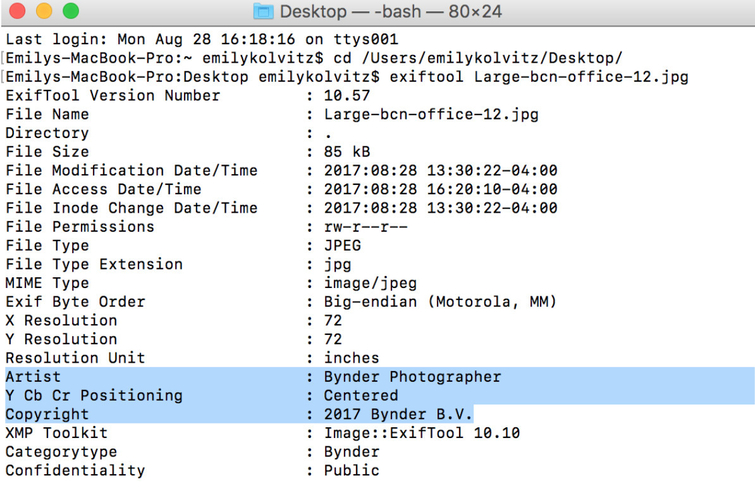
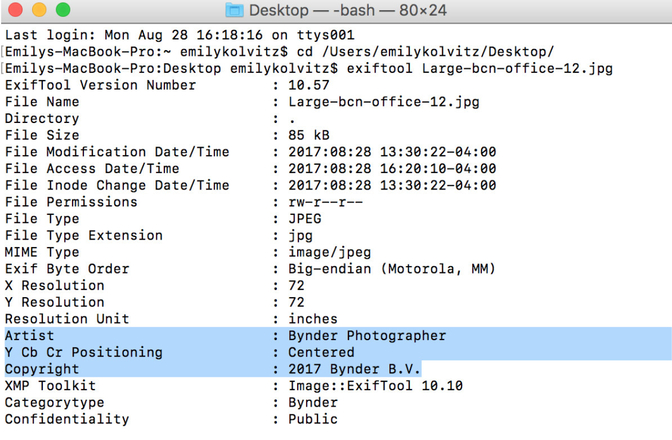
- Add some new data to a file. Type into the command line:
exiftool -artist="Bynder Photographer" -copyright="2017 Bynder B.V." thenthefilename.jpg |
(or the path to the folder instead of filename if you want to apply to all files in the folder)
Example:





Result: The fields “Artist” and “Copyright” were updated on that file with new values:
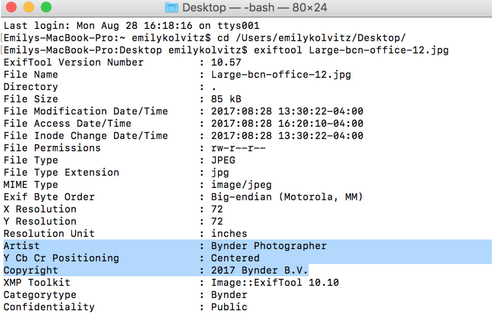
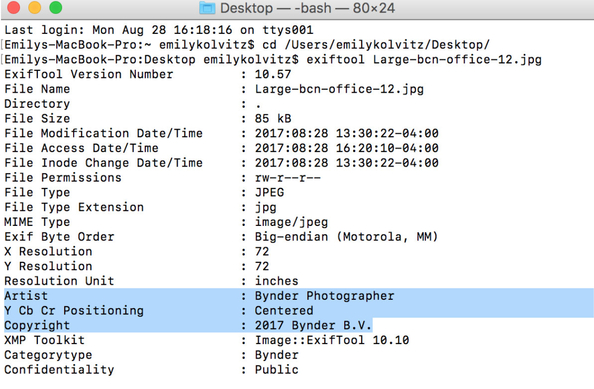
Exercise 3: How can I export embedded metadata from digital files to a .CSV file?
This exercise will help you migrate data and files from one system to another. Let’s say you have files on a local shared network drive and you want to upload them to a DAM repository. You may want to export all associated metadata to a .CSV file for a batch import along with assets, and apply additional metadata to the record for the file before ingesting. You may also want to check the data for quality before uploading it to a new system. Remember: good data in = good data out, and garbage in = garbage out.
- Type exiftool -csv filename.jpg > csvname.csv (replacing filename and whatever you’d like to name your new csv it will create.)
Example:





Output: This command makes a handy spreadsheet of all the embedded metadata
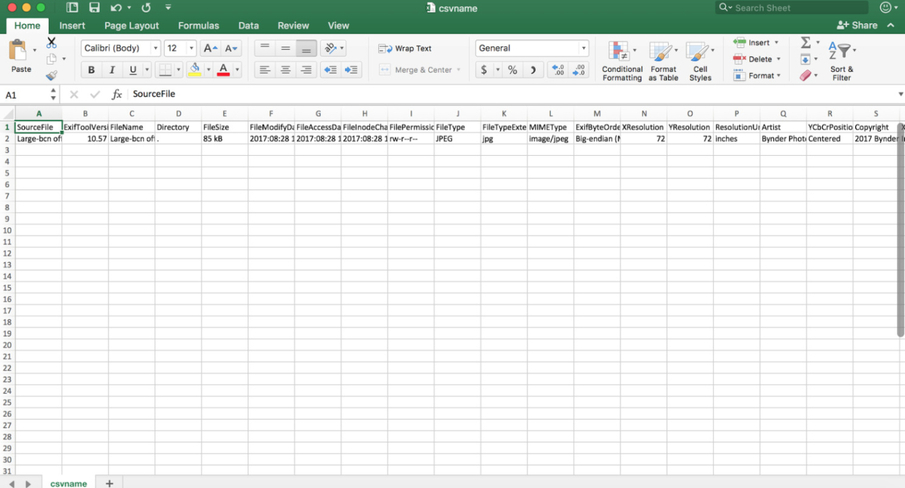
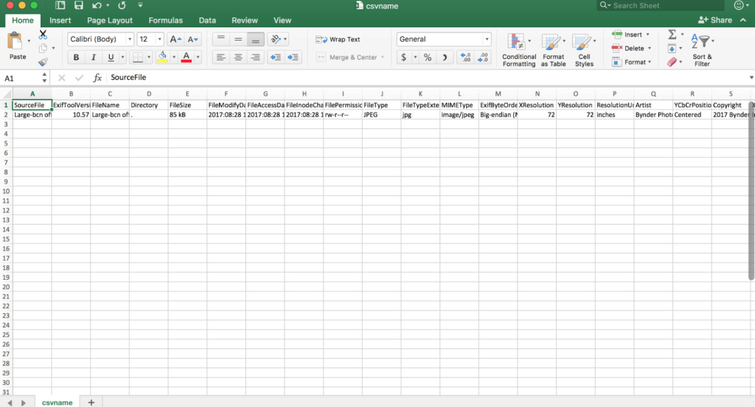
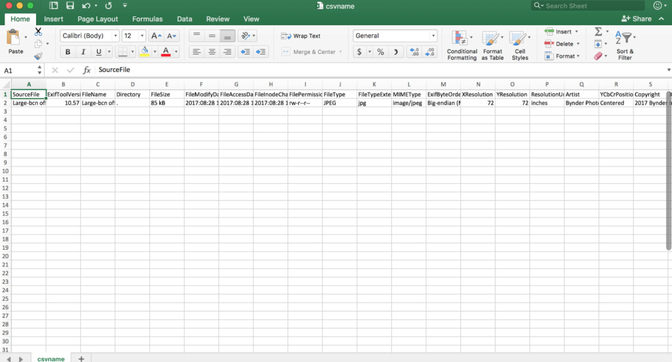
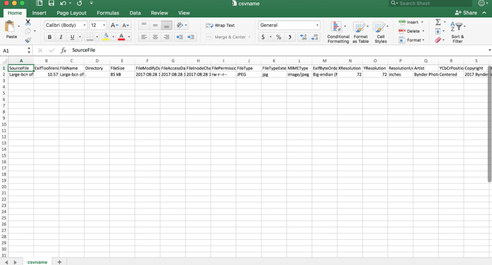
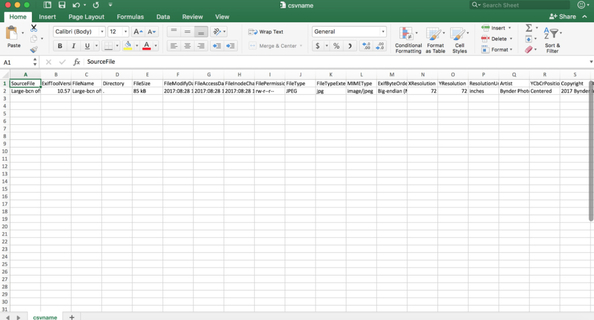
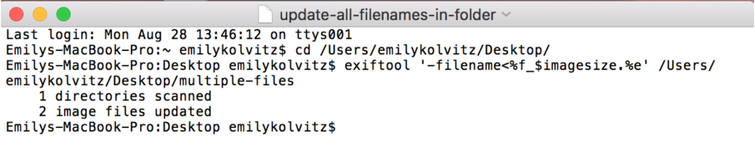
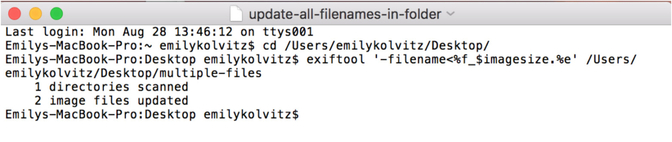
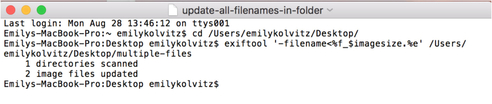
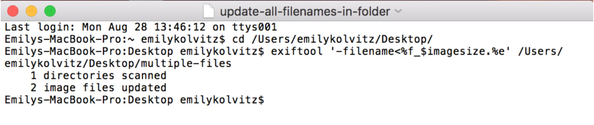
Exercise 4: How can I rename my files using embedded metadata?
Let’s say you don’t have a file-naming convention. This exercise can help you to create a file-naming convention from already existing metadata inside the file itself, or even just do some simple stuff like put the file dimensions in the existing filename.
- Type exiftool '-filename<%f_$imagesize.%e' /Directoryto/yourfiles
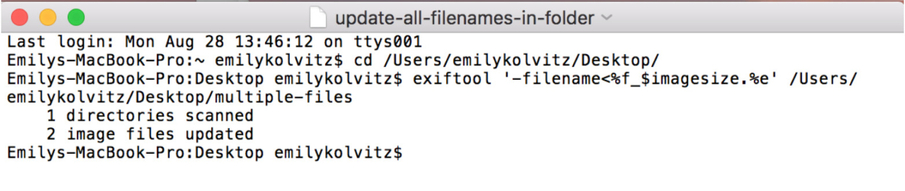





Exercise 5: How can I pair data from two sources onto a single spreadsheet?
This exercise is useful if you are combining data from disparate systems into one csv to enrich digital files. A prime example of this would be marrying product data to digital files, where you have an export of product data from one system without specific filenames, and an export of digital files and associated metadata from another system without the product data.
If you have SKU in your file-name, it’s easy to combine these two sheets using that common shared value, resulting in enriched digital files in an automated fashion.
Let’s say you have one spreadsheet with product data, including SKU, but no associated files. You also have one spreadsheet with filenames and a SKU. You can make one spreadsheet so that this data can be used to enrich digital assets before ingesting to a DAM system, or if you want to apply to the files as embedded metadata (as demonstrated in the next exercise.)
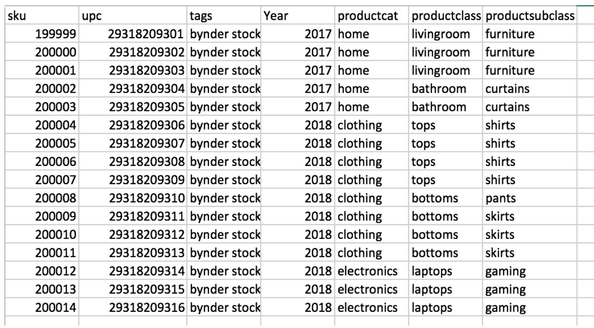
An example of the sheet with no filenames, but with a lot of product data:
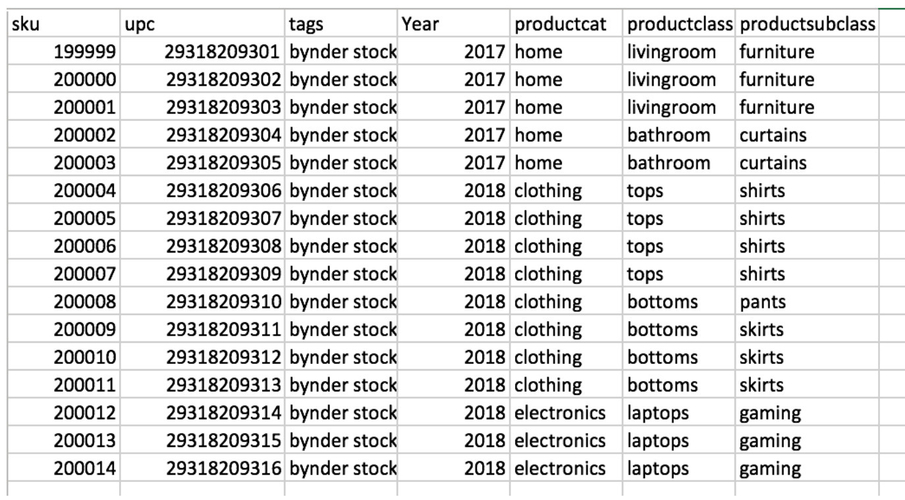
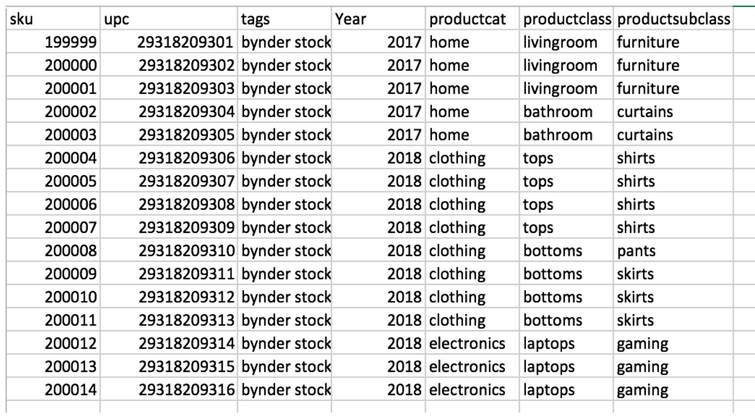
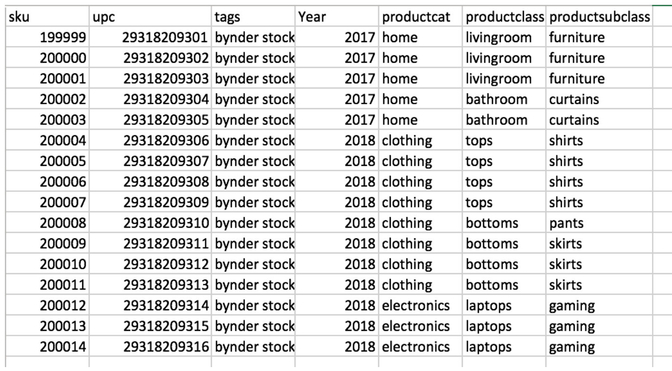
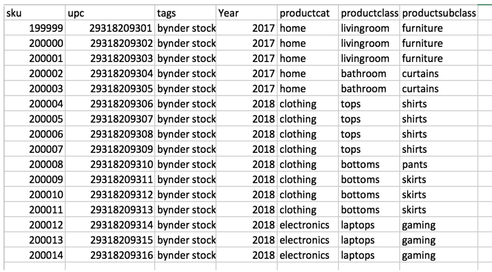
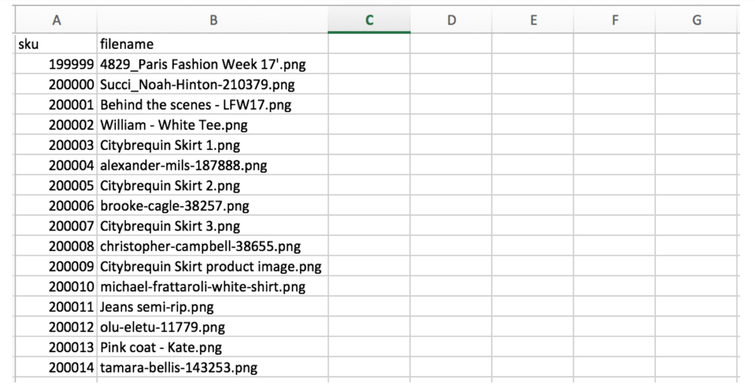
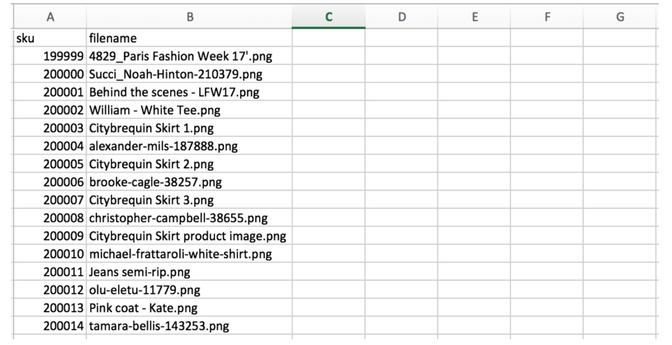
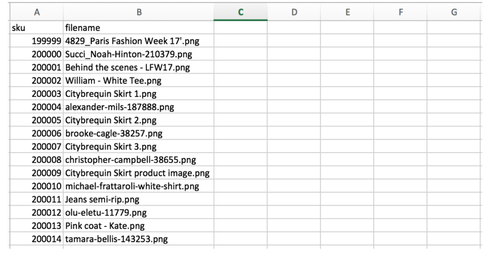
An example of the sheet with filenames and SKU, but missing the rest of the product data:

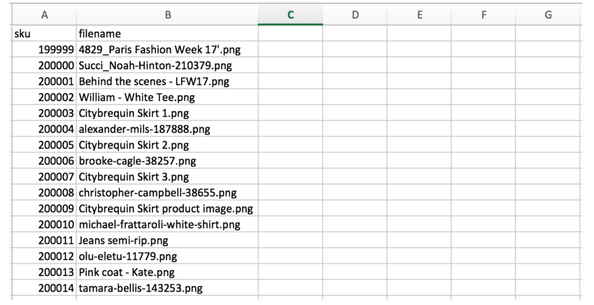
Here is the result when you ‘marry’ them together with a simple script:
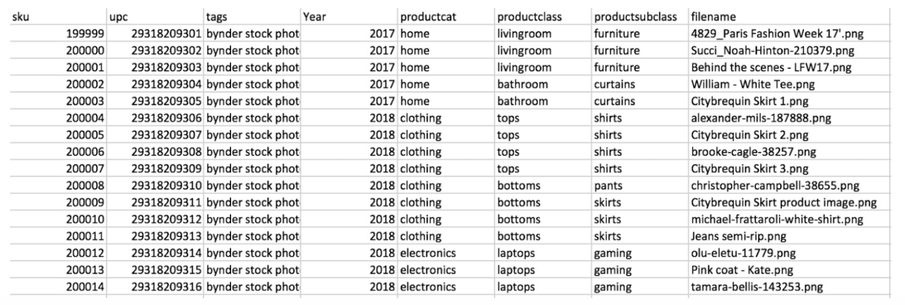
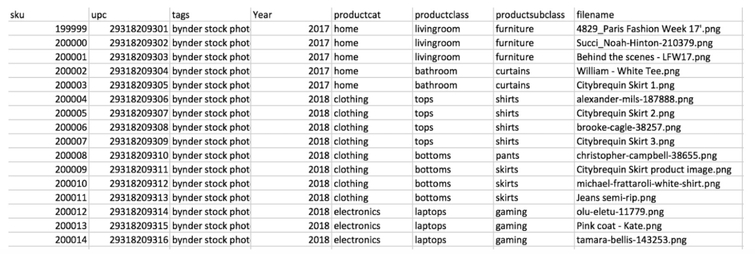
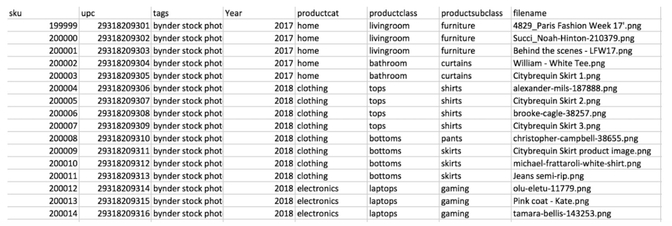
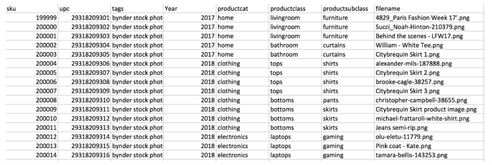
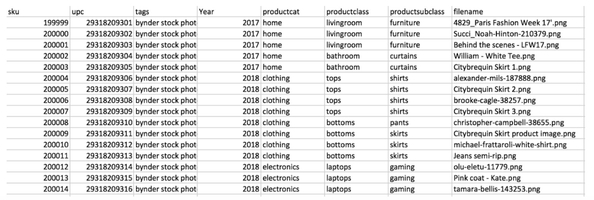
And this script is very simple:

Make sure your CSVs have at least one matching key/field. In this example, both of these CSVs have the field ‘sku.’ We will merge these files based on that common key using the ok.py script.
- First change the names of the CSVs in the ok.py script to reflect the names of the CSVs you are merging
- Open Terminal and cd to the directory where you csv files are
- Run ok.py by typing python ok.py
- Check out your merged CSV file. Easy!
Exercise 6: Using a CSV file to enrich your assets with custom/user-defined tags
Now, after completing Exercise 5 you may want to apply this data to a big batch of files. For some DAM systems, you’ll be able to ingest the spreadsheet along with the files to apply the metadata in the system itself, but maybe you also want to populate the embedded metadata on these files and have it map automatically instead.
To write this data to your files, you’ll need to pull out EXIFTool again:
1. Change the name of the ‘filename’ column in your CSV to ‘SourceFile’ and move it to the first column in the sheet
2. Update your Exiftool Config file with your custom namespace (name it whatever you feel is suitable) and xmp tag names
In this example, two quick edits have been made to the config file found at the EXIFTool site:
Edit 1: Adding ‘bynder’ after UserDefined on line 126:





Edit 2: Adding the namespace ‘bynder’ again as well as custom tags from lines 245-259:
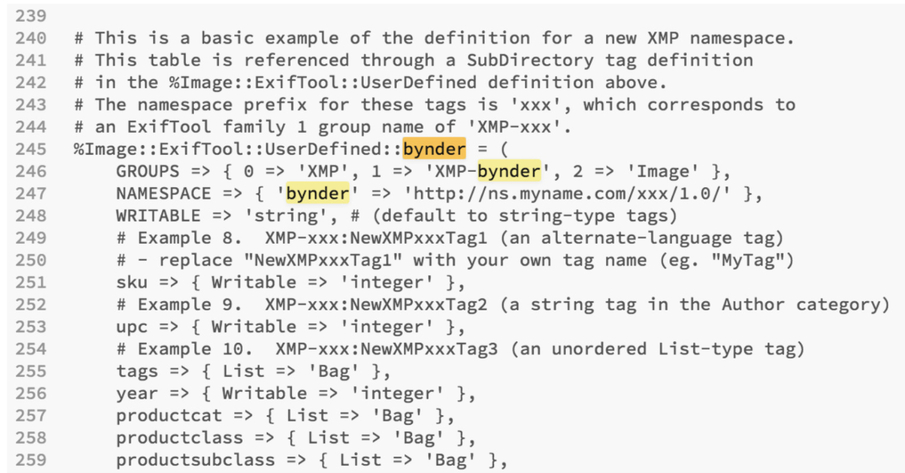
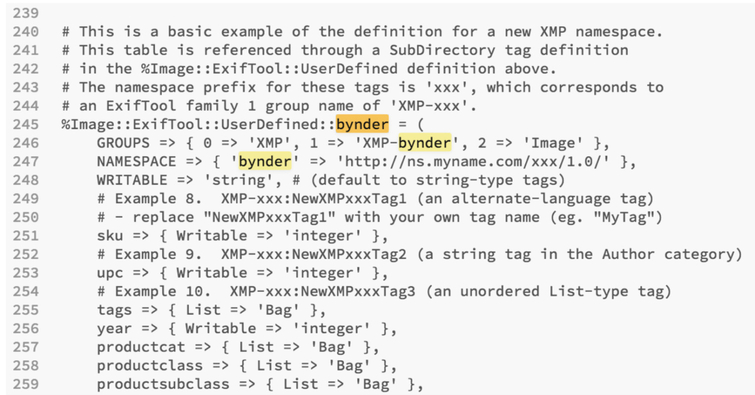
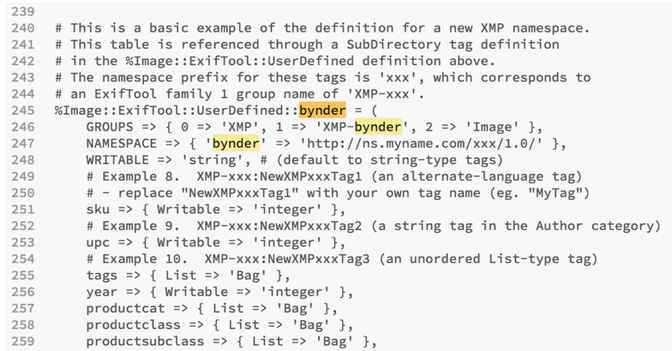
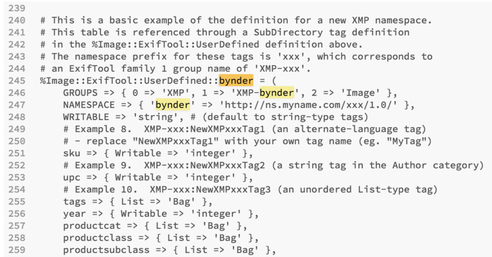

3. Save your file. Then you’ll have to move your config file to your directory where EXIFTool is run (rename it as you move it, i.e. mv /Users/emilykolvitz/Desktop/config /Usr/local/bin/.ExifTool_config )
Now that’s done, ready to check it out?
- Open Terminal
- Type exiftool -csv+="name of csv file" -r .
- Check out your updated files metadata by typing “Exiftool -X filename.jpg”





So you’re now able to add your own custom namespace and user-defined tags to your digital assets.
Embedded metadata exercises in DAM systems
Finally, you may wonder how this information can be ingested into your DAM. DAM tools differ in how they are configured and set up, but with many of them you can specify what data fields you’d like to map to when ingesting files, and also what data you’d like to export when downloading files. In most DAM systems, you should be able to:
- Map embedded metadata from files to a DAM taxonomy
- Ingest files and a spreadsheet with metadata at the same time
- Use the API to enrich digital assets with additional metadata or to upload files and add metadata simultaneously
- Save data applied in the DAM system to embedded metadata fields
- Export embedded metadata from a DAM system
It’s also important to note that in some DAM systems, certain fields are mapped automatically without configuration on the part of the administrator, whereas some fields need to be configured to map correctly.
Example of mapping Dublin Core rights (dc:rights) upon ingest and also export:
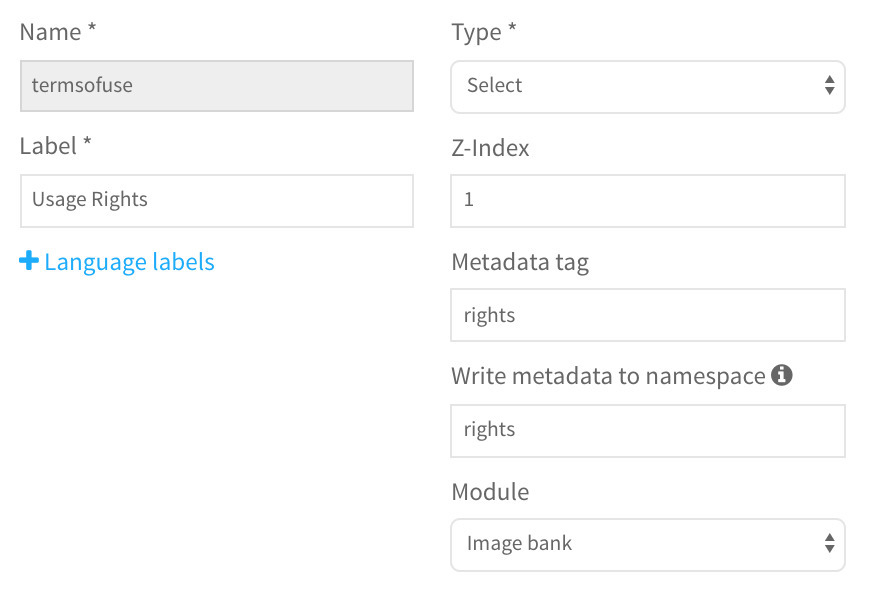
When should I use embedded metadata and when shouldn’t I?
Sometimes you may want to use embedded metadata, and other times using embedded metadata is not the standard practice (such as on e-Commerce websites.) It can be tricky sometimes to figure out when to use embedded metadata and when to avoid it.
You should use embedded metadata when:
- You want to document provenance and asset lifecycle for digital file authenticity and good record keeping
- You think this data will be useful for the future
- You know that it’s required for an automated metadata workflow (i.e. when you’re under contract to apply this data for a company or business when working with their digital files)
- You work with library and digital archives collections (and if you’re not doing this, you should start!)
- You want to ensure right to use data travels with the file
You shouldn’t use embedded metadata when:
- You’re not sure if the embedded metadata is reliable or accurate
- The data you’re applying is sensitive or confidential in nature
- It doesn’t provide added value
Embedded metadata initiative
Finally, one really useful resource about embedded metadata is the embedded metadata initiative that is definitely worth checking out. In 2016, they did an extensive survey of social media sites to see which ones preserved and maintained embedded metadata during ingest, or upon download, which you can view here: https://www.embeddedmetadata.org/social-media-test-results.php.
Are you ready to compare DAM vendors? Click below to get the DAM Comparison Guide!


